Artificial Intelligence (AI) made significant waves in 2023, impacting everything from the high school essay to big business. When it comes to healthcare SEO, AI is certainly shifting the landscape and redefining what type of content can move the bar in organic. Within this new paradigm, originality, quality, and authenticity are paramount if you want to rank on Google in 2024. To help you navigate this new world of SEO, here are the top trends and recommendations we think you should incorporate into your 2024 healthcare SEO strategy.
Table of Contents
- 1. In AI-generated World, Content Quality is Crucial
- 2. SERP Features Only Available to Authoritative Sites
- 3. User Experience Remains Paramount
- 4. Social Media’s Rising Impact on SEO
- 5. Growing Demand for Real Authenticity
- 6. SEOs Need Integrated & Compliant Tech Stack
- 7. Google Makes Search More Friendly for Healthcare Consumers
1. In AI-generated World, Content Quality is Crucial
New AI content-generating tools transformed the marketing world in 2023, changing how marketers generate content. As much as some may hem and haw, AI is here to stay.
AI technologies like ChatGPT have proven to be helpful research and marketing tools, providing initial research for content and even generating content in some instances.
What does this mean for your healthcare SEO strategy? For one, creating mass volumes of content is no longer a relevant SEO strategy. It didn’t work well before, and it works even less now. Just cranking out articles isn’t impactful any longer—after all, anyone can do that now, and it’s become even easier with AI. What should you focus on instead? Those two stalwarts of SEO—quality and originality.
Use The E-A-T Model and YMYL Guidelines for Content
When creating website content, follow Google’s E-A-T (Expertise, Authoritativeness, and Trustworthiness) model. EAT model affects each industry differently. For healthcare marketers, EAT impacts your rankability and determines how efficiently you can build trust with your audience—which is vital to effective online patient acquisition.
Use existing SERPs as your guideline for developing content that builds your EAT. For example, what are the similarities between the top 3 results from multiple queries under the same topic?
To develop EAT-centric content, follow these best practices
- Create original, relevant, and updated content. If necessary, revamp a previous article to provide more recent information.
- Be honest and transparent with your content.
- Understand the Topic Coverage Score (TCS) of your chosen topics to avoid writing about a question oversaturated with answers.
Meanwhile, healthcare marketers should also be aware of the YMYL (your money or your life) guidelines, especially for urgent care providers, emergency rooms, and other time-sensitive treatment providers.
Simply put, YMYL content is high-urgency content tailored to move problem-aware MOF leads into the decision-making stage. Therefore, healthcare marketers can turn their website content into a lead-generating machine by combining EAT and YMYL models.
Be Original
As for originality? Being “original” in your content can mean exploring unique angles. Consider adding your unique take on content rather than regurgitating what already exists online. Of course, in healthcare, that doesn’t mean that you can just go with any notion. Any content you generate in the healthcare space needs to be vetted, accurate, and held to the highest standards. Never sacrifice quality in pursuit of originality.
Your healthcare practice or organization has its own unique approach, however. Use this opportunity to highlight the one-of-a-kind approach and patient experience that your healthcare institute brings to the table. What do your providers wish more patients knew? How can you address questions that often get ignored? Dig deep here to find out what patients want to know, what information gaps exist, and introduce your authoritative and original voice and answer into the mix.
Invest in Your Authorship
Another area that should have your attention? Authorship. As AI gains more and more prominence, users will want more assurance that the information they are getting is from a trusted human authority. Sources and authors are more important than ever.
Feature your founder, executive team, or doctor as an author and show that a real person is involved. You know how relevant the personal touch is in healthcare and how much patients want to establish trust. This is a great way to do it. Having an actual doctor or expert associated with your brand’s content increases your brand’s credibility.
All of this will impact entity building, which will be a big part of SEO moving forward. Every time you deliver authoritative and authentic content, you are giving Google more clarity on your entity. When patients ask questions about your services, Google will have what it needs to give the right answers— and answers that are advantageous to your brand. Make sure Google understands who you are and why you deserve to have it rank your websites.
2. SERP Features Only Available to Authoritative Sites
Speaking of “authoritative,” did you know that Google is making it more difficult to secure a featured snippet at the top of search results? A recent update revealed that moving forward, “FAQ (from FAQPage structured data) rich results will only be shown for well-known, authoritative government and health websites.”
The good news is that healthcare websites will have a better chance of making it into the FAQ since they are typically the only ones that will be featured there (along with government sites.) That doesn’t mean it’s a guarantee, however. You will still need to have a strong backlink profile, and you will most definitely need to have an authoritative site.
What do you need to do to ensure this? Invest in a strong digital PR strategy, for one. Double your link-building efforts, as well. All of this will be key in growing the authority of your site and increasing your opportunities to rank and secure a featured snippet like an FAQ.
How Link Building Can Help You Secure Snippets
Want some tips to ensure your link-building efforts help you secure snippets? We recommend the following:
- Invest in a digital PR strategy starting now and throughout 2024.
- Join professional organizations and seek publication opportunities. This means submitting to leading industry publications with national profiles.
- While national backlink sources that produce national recognition are important for large healthcare brands, don’t forget your local backlinks. High-quality local backlinks are valuable because Google prioritizes healthcare providers that are closest to its searchers.
- Use HARO to monitor opportunities. “Help a Reporter Out” is a service that allows you to connect with other content generators and monitor source requests. Use this service to keep an eye out for any and all source requests that are relevant to your healthcare niche or your organization’s expertise.
3. User Experience Remains Paramount
Remember: Google wants to offer exceptional digital experiences for its users‒and this focus on UX will not dissipate. Therefore, your website’s functionality and user experience are paramount. If people can’t find the information they need quickly and bounce, it signals to Google that your site shouldn’t be ranked highly.
Almost two years ago now, Google’s Page Experience Update rocked the Internet and website owners. Its focus is “a set of signals that measure how users perceive the experience of interacting with a web page beyond its pure information value.” The Page Experience Update (effectively a UX update) considers Core Web Vitals metrics, mobile-first design, site security (using HTTPS), and interstitial behavior (regarding pop-ups and ease of use).
If you haven’t updated your website to comply with these new ranking factors, you need to continue to prioritize that throughout 2023. Google’s relentless drive to create the optimum search experience will only continue. If your healthcare group doesn’t offer a good digital UX, you’ll struggle to have visibility on search.
Run your site through Google’s page speed tool or any technical auditing tool, and you may be surprised that even a brand-new WordPress site returns a dismal result.
To thoroughly improve your website’s user experience, you should:
- Conduct regular site audits
- Keep your website’s software updated
- Improve communication between your development and marketing teams
- Minimize plug-ins and ensure your WordPress theme meets UX metrics
- Replace pop-ups with clear on-page CTAs
UX Optimization Best Practices
The best time to optimize UX is the beginning of your website project. If you treat UX as an afterthought, you’ll pay a hefty price. That said, on-site SEO can be intimidating and full of nuances. Therefore, we put together seven simple principles to guide your optimization effort.
- Organization: Keep your site structure organized with clean and sensible navigation.
- Discoverability: Ensure visitors can find the most important pages (location, book an appointment, specific treatment they need) on your website easily.
- Uniqueness: Create unique content and image assets to distinguish yourself from competitors and avoid Google marking your content as duplication.
- Linkability: Create a meaningful internal linking structure while earning links with quality, professional content. Launch a backlinking campaign for better results.
- Consistency: Maintain visual consistency throughout your website.
- Value: Provide comprehensive, in-depth information to thoroughly answer consumers’ questions.
- Speed: Again, modern consumers want fast websites. Make sure your pages load quickly.
Learn more about UX optimization principles.
4. Social Media’s Rising Impact on SEO
Plot twist—social media is back and impacting SEO in 2023. Google’s Gary Illyes recently announced that your credibility on the web and on social will influence how quickly your website can be indexed. Why is this?
AI-generated content is flooding the Internet, and Google can’t index everything as quickly as it once could. As a result, they will need to prioritize some content first. To understand what content to index first, Google is looking for certain signals.
Moving forward, social will be part of that process. Google will index the content that seems more credible and engaging first, and it’ll be using social cues to determine that. It will be looking to see if you have an active social media profile, for one. Beyond that, it will be looking at whether you have a solid number of followers and how high your engagement is. Given all that, it’s time to put effort into your socials and make sure that your patients and potential patients are engaging. If you do that, you just might help your search rankings get to the top first.
How to Use Social to Improve Authority and Indexing Speed:
Here are some tips we recommend for increasing your brand’s social relevance:
- Make sure all of your brand and executive leaders are active on LinkedIn. This doesn’t mean creating a profile and leaving it to stagnate!
- Build a reputation for sharing thoughtful, helpful content. By consistently sharing content, you will buoy your brand’s authority in the space and attract much more impactful engagement.
- Connect with relevant contacts and build your network. The more quality contacts you have, the more reputable you’re brand will appear to social users.
5. Growing Demand for Real Authenticity
We can’t say it often enough—healthcare consumers (and consumers in general) want to hear real voices. Consumers want information from people like them and people that they can trust. With the advent of AI, it’s getting harder for users to trust that their search results are not just AI content.
Earlier this year, Google launched its new Perspectives feature to address this issue. When consumers search for a topic that could benefit from the perspectives of other (human) users, they will see a Perspectives filter at the top of their search results, where they would typically see common filters such as Images or News. According to Google, by clicking on the Perspectives filter, users can access “long- and short-form videos, images and written posts that people have shared on discussion boards, Q&A sites, and social media platforms,” as well as “more details about the creators of this content, such as their name, profile photo or information about the popularity of their content.”
In many ways, Perspectives is a game changer. It’s definitely impacting the SERP, and it’s truly showing different POVs and perspectives. Given that, SEOs will have to think about social media and how that content impacts the SERP.
For marketers, this all underscores the growing demand for authentic content and the undeniable impact of video in today’s digital landscape. That’s why it’s essential to ensure your strategies prioritize genuine engagement and embrace video storytelling.
Marketers Must Use Video and Social as Part of Their SEO Strategy
When we say “embrace video storytelling,” we don’t mean make some room for it. Healthcare groups have to prioritize video and real people in organic content as part of their overall patient acquisition strategy.
In healthcare, that means providing a face with a name for your doctors. It also means you need to put a lot of effort into building your brand’s social media presence, including being active on channels like TikTok. Google can pull all of that video content into Perspectives and the SERP, giving your brand that personal, authentic touch healthcare consumers are looking for.
Wondering how you can generate video content with your doctors? Here are some ideas to consider:
- Interviews – A video interview will give consumers a chance to get to know your providers and increase their comfort and trust levels with your brand.
- BTS or Tour Videos – Consider doing a “behind the scenes” video or tour of your practice. Again, this will put a human face on your brand and make your potential patients trust you that much more.
- Explainer Videos – A video with your doctor explaining one of your most common procedures is a great way to overcome resistance, share relevant information, and humanize your practice.
6. SEOs Need Integrated & Compliant Tech Stack
Even if you execute all of the above perfectly, you won’t get what you need out of these efforts if you don’t have your analytics tech stack in great shape. Your analytics tech stack for organic has to be airtight. While businesses will often prioritize tracking solutions and analytics for media, they don’t necessarily always do that for SEO.
That’s a big mistake. Mostly, it comes from a lack of understanding of SEO’s impact on the bottom line.
SEOs need to connect the dots to revenue and push for the systems to make it happen.
There’s a lot more to tracking for SEO than a last-touch attribution model. You need to understand how healthcare consumers are using your website, engaging with content, and what moves them through the patient journey. The tech stack you use needs to be well-integrated and set up from the beginning if you want to connect the SEO dots to revenue.
Navigating HIPAA Regulations
The go-to analytics solution for many marketing teams has long been Google Analytics. While a hugely popular and effective tool, it is not inherently HIPAA-compliant. Google places the onus directly on marketers, stating that users should not pass any data to Google “that Google could recognize as personally identifiable information (PII)” or that could be considered PHI.
Again, Google has been very clear that GA4 is not HIPAA-compliant:
“Customers must refrain from using Google Analytics in any way that may create obligations under HIPAA for Google. HIPAA-regulated entities using Google Analytics must refrain from exposing to Google any data that may be considered Protected Health Information (PHI), even if not expressly described as PII in Google’s contracts and policies.”
Why is it so difficult for Google Analytics to remain compliant? Consider this example: Say a woman in LA is looking for addiction treatment. She runs a search for “addiction treatment Los Angeles” and then clicks on the link to your site from the SERP.
The GA4 toll collects your URL and the woman’s IP address. When those two pieces of information are put together—i.e. a patient’s PII and your URL—you have a violation of HIPAA regulations.
How to Build a HIPAA-compliant SEO & Marketing Analytics Solution
How can you build an SEO and marketing analytics solution that is HIPAA-compliant? We recommend two primary solutions:
Use a new analytics platform
New analytics platforms can be configured in a way that makes them HIPAA-compliant. One such option is Mixpanel— when you purchase a subscription, you are considered a “Covered Entity” under HIPAA and can execute a Business Associate Agreement with Mixpanel. Other options to consider? Heap and Amplitude are designed for easy integration with your existing ecosystem of digital solutions.
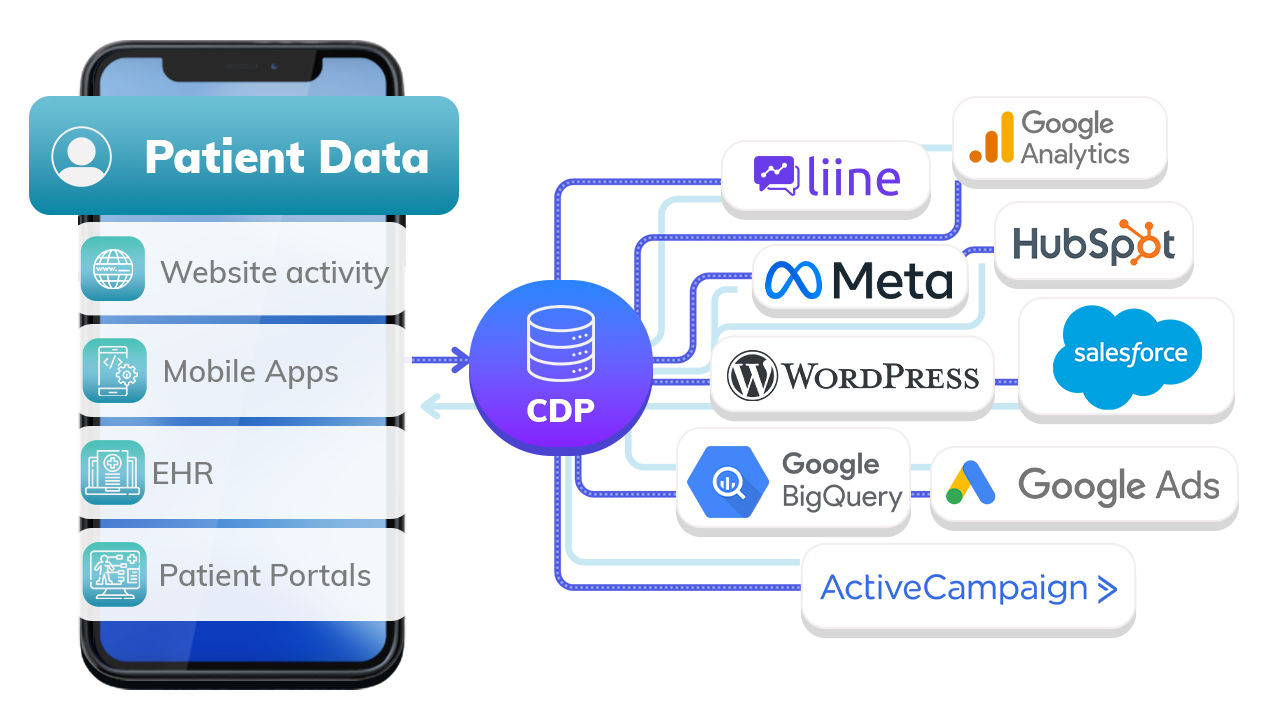
Implement a CDP
Another option to consider is implementing a CDP. What is a CDP? A CDP is a Customer Data Platform. In this context, it sits between GA4 and your website to ensure that data is handled in a way that is HIPAA-compliant. Usual techniques used to do this include masking user identities and creating lists that limit which data is sent to a non-compliant destination, such as GA4. Which CDPs should you consider? We like Freshpaint, as well as Rudderstack and Segment.
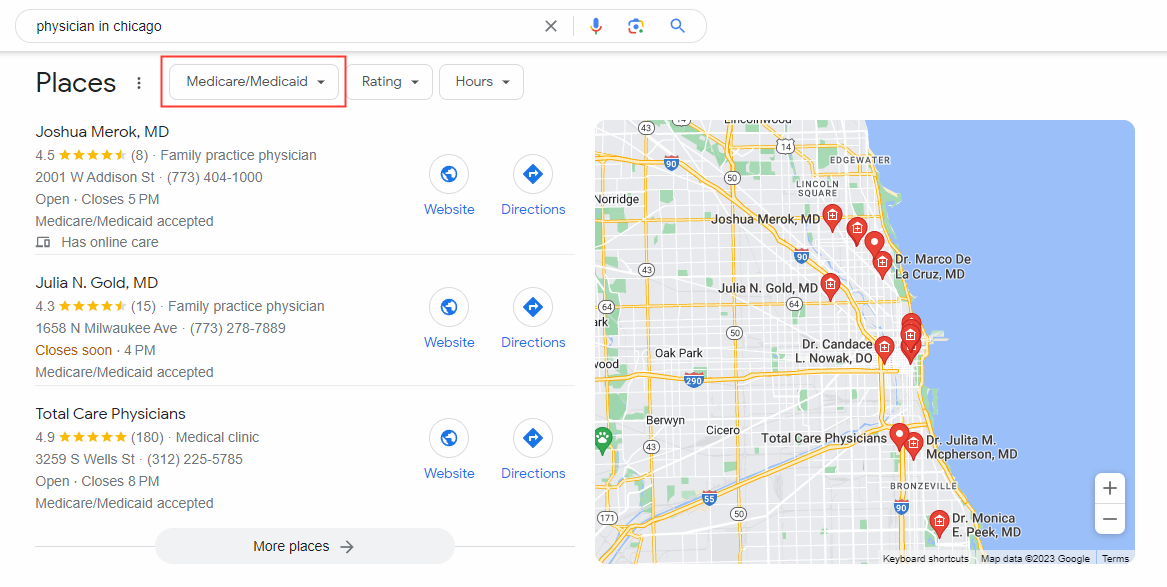
7. Google Makes Search More Friendly for Healthcare Consumers
Finally, make sure to leverage the new search features Google has introduced to make health information more accessible to users. This includes Med-PaLM 2, a medical-specific LLM that essentially functions like chatGPT… but with a stethoscope. This feature is designed to facilitate rich, informative discussions around medical topics, answer some of the most complex medical questions, and deliver insights into medical texts that might be too complicated or unstructured for the average user.
Google is also providing Medicaid and Medicare highlights to facilitate healthcare searches. Search results related to these topics will populate with multiple buttons that direct them to relevant information. Users looking to enroll in health benefits through either program will get access to information on eligibility and details on the application process. When healthcare consumers run a search for local physicians, Google will include whether those providers accept either Medicare or Medicaid, too.