

Many website owners pay little attention to duplicate content because they don’t understand the repercussions of it. However, if you are continuously posting duplicate content, it could spiral into a big problem for your website. One problem that’s a direct cause of this is a drop in organic traffic to your website.
Table of Contents
- Problems with Duplicate Content
- 1. Perform 301 redirects
- 2. Use noindex tags
- 3. Use canonical tags
- 4. Use hashtag tracking
- 5. Use rel=“next” and rel=“prev” for paginated content
- 6. Use hreflang
- 7. Set preferred website version on Google Console
- 8. Submit sitemap
- 9. Ensure robots.txt file is functional
- 10. Avoid using nofollow attribute on internal links
- 11. Avoid keyword stuffing
- 12. Make your website mobile-friendly
- Conclusion
According to Google, 25-30% of all content on the web is duplicate content.
However, although Google doesn’t penalize your website for duplicate content (at least, not directly), most websites see a drop in traffic due to the way search engines work. When a person conducts a web search, they want to see relevant results, not duplicated copy from another webpage. So it’s only a no-brainer that search engines adjust their algorithms to match the searcher’s needs. If two or more URLs on your website point to the same page, it confuses the search engine, and then you’re forcing it to decide which result is the most relevant among the two or more pages with the same content.
In many cases, Google picks one result. That’s why you see something like this at the end of some search queries:

Problems with Duplicate Content
The issue with this is that your preferred page may not be the one Google decides to show in the search results. And, there are other issues you could encounter with duplicate content, such as:
Low authority:
When you have duplicate content on your website, instead of a single page having 15 inbound links to it, you may have three pages of the same content sharing five links apiece. This makes each version weaker and less likely to rank than a single version of the page.
Wrong content for visitors:
If you are trying to appeal to an international audience with SEO, the German version of your page could be showing up for your French visitors which is bad for business and a waste of time and effort.
Some causes of duplicate content are:
- www vs. non-www or http vs https version of a page
- Scraped or copied content
- URL variations
What if your website pages are not showing up on search engines? This could be because your pages are not indexed. In a situation like this, there’s no way those pages will get search traffic.
This post will show you how to prevent these types of issues on your website, but before we go on, how do you know if your website has these issues?
One simple way to know is to search the string “site:yoursite.com” on Google and see what comes up.
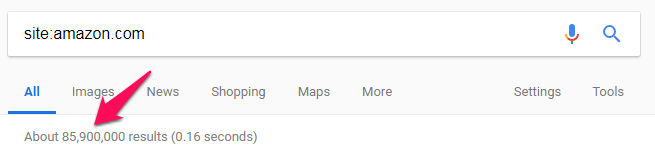
If it’s far higher than the number of pages on your website, then you may have pages of duplicate content. If it’s far lower than what you expected, then you probably have indexing issues.
Below are 12 possible solutions to improve your website’s rankings:
1. Perform 301 redirects
In some cases, the best solution is to perform a permanent 301 redirect from other similar pages to the page you want to rank on search engines. This is usually needed when you have a page that may not be exactly the same but have similar content and is more likely to rank for the same keywords.
When you perform a 301 redirect, the other duplicate pages become unavailable as their traffic is automatically directed to your preferred page. With this, you also don’t have to worry about the authority and ranking power your redirected pages have gained.
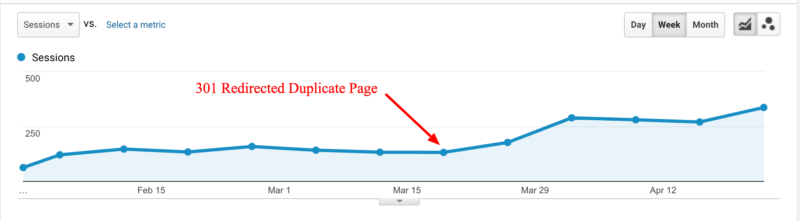
About 90-99% of the link equity gained by the duplicate pages are transferred to your preferred page.
When one large company advertiser decided to perform a 301 redirect to eliminate one of their two similar pages, this led to a 200% increase in organic traffic to the page.
2. Use noindex tags
If there’s a page on your website you don’t want Google or other search engines to rank, you have to add the content=“noindex,follow” meta robots tag to the page. This means Google will be able to access the page and see its content without adding it to its index.
It’s important to allow enough time for the search engines to follow the page because in some cases there may be an error in coding and you can let the search engine decide if that page is the right one to appear in search engines. When the bot discovers this, it will disregard your command and index the page anyway. The noindex tag is especially applicable for pagination issues where you want only the first page to appear in search engines rather than all 10 pages.
To implement the noindex tag, add the line of code shown below into the head section of the page’s HTML code.

3. Use canonical tags
The rel=“canonical” tag is common for pages as it adds parameter tracking to their website to document the source of its traffic (and it’s also used for affiliate marketing purposes). These different URLs for the same page may lead to problems of duplicate content.
It’s necessary to add rel=“canonical” tags to the URLs with the parameters as this tells the search engine that your preferred original URL should rank higher rather than the other variations of the URL. Also, the links and other ranking power gained by the duplicate pages are transferred to your preferred address.
To implement this code in your content, enter the code shown below at the top of the HTML duplicate page:

Replace “URL OF ORIGINAL PAGE” with the address of the page you want. Below is an example of a canonical tag on a Buzzfeed page.
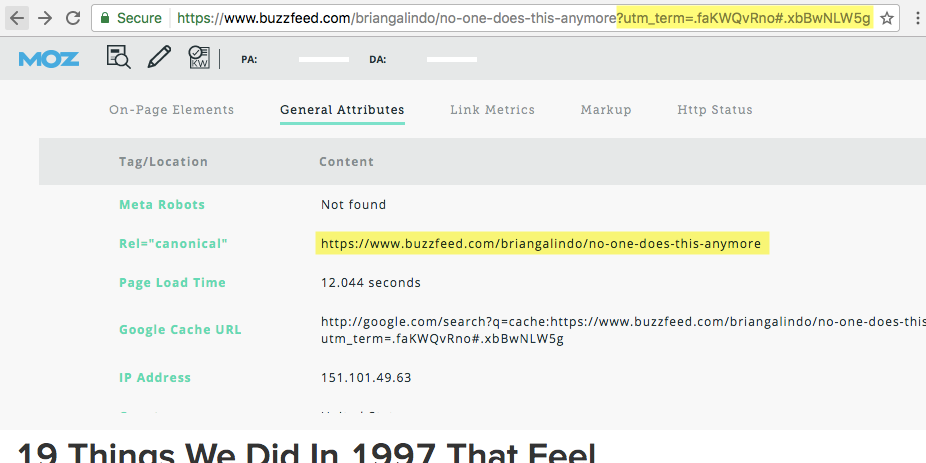
It’s important to note that you should not use the noindex and the canonical tag at the same time.
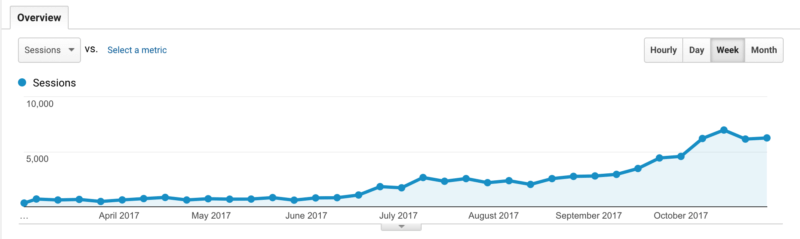
In this example, using a canonical tag to eliminate duplicate pages caused by parameters allowed a business to increase organic traffic to that page by 800%:
4. Use hashtag tracking
One way to prevent parameter tracking from evolving into a duplicate content issue is to use hashtag tracking.
For most URLs that track parameters, they have a structure like “https://yoursite.com/page/?” and the parameter after the question mark.
The problem is that search engines see this as a different page to the original page.
A page with a URL structure like “https://yoursite.com/page/#” followed by your parameters will be seen as “https://yoursite.com/page/”. This eliminates the issue of duplicate pages for that page.
![]()
5. Use rel=“next” and rel=“prev” for paginated content
If you have content that contains series of pages, you may need to add a to tell Google that the pages are in a series and that it should start from the beginning of the series which is the first page.

Google has stated that you don’t need to take action for paginated content and it will sort it out. However, there’s no harm in helping out your cause.
For instance, if you have 4 pages in a series, you can add this code in the section of each page. For the first page, you can add the code below:

For the second page, you can add this:

For the third page:

And for the last page:

You’ll notice that the first and last pages only have rel=“next” and rel=“prev” respectively (at the beginning and the end).
6. Use hreflang
When you are marketing to an international audience with SEO, you don’t want your audience to see your page in a foreign language because that would make your content irrelevant and you would gain neither a lead nor a customer with such a page.
To eliminate this potential situation, you have to specify the language for each particular page. This tells search engines what page to show to Spanish-speaking viewers, English-speaking viewers, or whatever country your visitation is coming from.
To do this, you have to add the hreflang annotation on your page. Here’s how to add the line of code for HTML and non-HTML pages on your website:

This will eliminate the possibility of Google seeing these pages as duplicate content, and it also helps to serve the right content to the right audience.
In some other cases, you might want to consider additional specifications for different countries that speak slight variations of the same language. For example, people in Europe, the United States, and Canada all speak English but put their own spin on it. To accommodate these variations, use the code below:

Be sure to use the right country codes too, such as “gb” instead of “uk.”
7. Set preferred website version on Google Console
To prevent a www vs. non-www version issue for your website, you can set a preferred version through your Google Console dashboard and set how Google will handle your URL parameters.
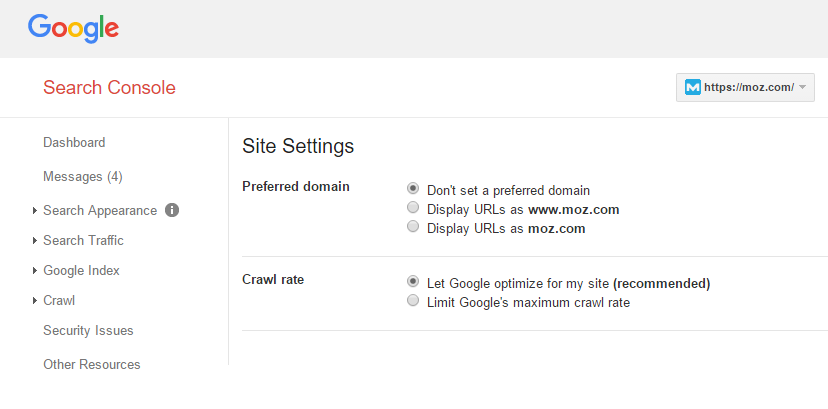
You can do this under the crawl section. For instance, you may have parameters that indicate countries of targeted consumers. Through the crawl section, you can edit current parameters or add new ones. However, if you’re not sure how to do this then don’t attempt it as you may end up incorrectly excluding important pages from the index.
And keep in mind that this is only for Google—you’ll have to repeat the process for other search engines.
8. Submit sitemap
Your website’s sitemap is an XML file that contains all of the URLs on your website. It’s a way of presenting your index to search engines in an organized manner and in turn it helps search engines crawl your website.
Here are some tools you can use to generate sitemaps if you currently don’t have one. If you run a WordPress site, the Yoast SEO plugin helps you to do this.
To add your sitemap to Google Console, go to your dashboard and click on sitemaps:
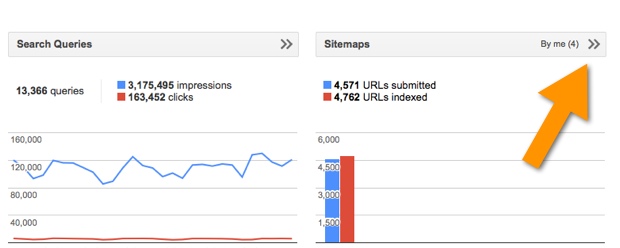
Then, click on the arrows that indicate more options and you’ll see an option to add or test your sitemap:
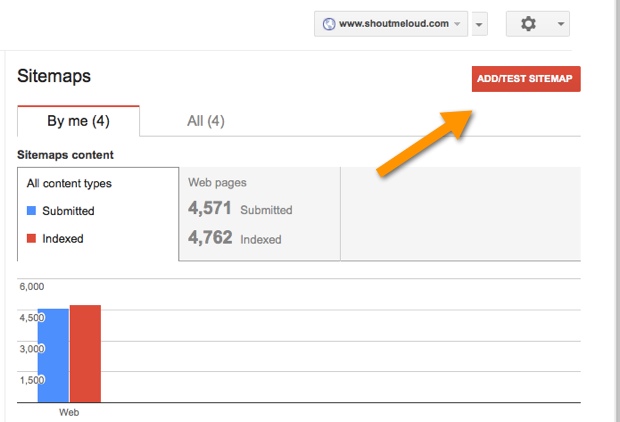
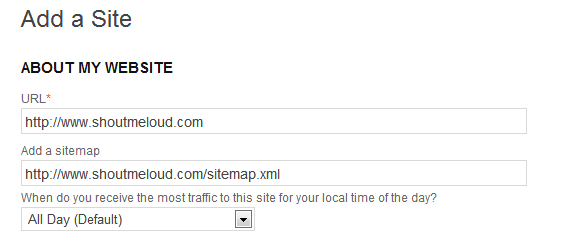
After typing the sitemap address, submit it:
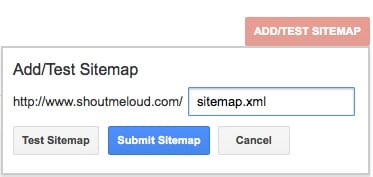
You can repeat the same process for Bing and also add the sitemap to the info page:
9. Ensure robots.txt file is functional
A robots.txt file helps search engines to know what pages to crawl and the ones to avoid. When a search engine bot gets to your website, they access this file to know what to do in crawling through the pages of your website.
If your website has no robots.txt file, the search engine bots still crawl it but without restrictions.
If you have a robots.txt file on your website, make sure that you’re not restricting search engines from crawling important pages.
With your optimized robots.txt file, you can restrict specific bots from crawling your website or set a delay before they do so. This is an example of a robots.txt file for Buzzfeed:
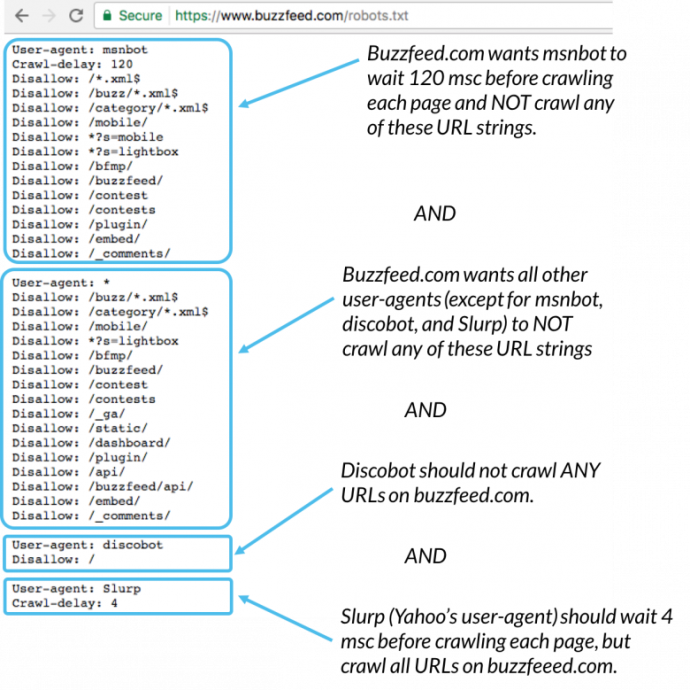
You can view your website’s robots.txt file at https://yoursite.com/robots.txt to see if you have one and what it contains.
10. Avoid using nofollow attribute on internal links
Due to poor external links, many websites find themselves adding the nofollow tag to links. But to make it easier, a lot of webmasters add the nofollow tag at the page level as well. However, when you do this, you may be doing harm to your website because the nofollow will apply to all your internal links from that page. And these internal links won’t pass the necessary link juice that they should be feeding to your internal pages.
By doing this, you are reducing your probability of ranking your own pages. You can add the nofollow tag to external links but don’t do it for internal links. This is what SEO expert Patrick Stox thinks about it:

Sometimes lines of code like this could be a problem to a website as well. Glenn Gabe gives an example of a website that used the noindex/nofollow tag on every page of its website, which led to having none of the pages indexed on Google:

11. Avoid keyword stuffing
Keywords are an important part of ranking on search engines because when a keyword appears multiple times in your content, you have a higher chance of it showing up in search results than a post without the keywords.
However, in trying to rank for keywords in search engines like Google, content marketers may stuff their content with keywords and end up choking it.
Keyword stuffing is a black hat SEO tactic that could incur a penalty and the pages could be removed from the search index.
One way to avoiding keyword stuffing is to first think about producing meaningful content for your audience before thinking about the Google bots. Likewise, writing longer posts allows you to include your keywords without having a keyword density that’s too high.
12. Make your website mobile-friendly
In the past, website owners usually concentrated their efforts on making their desktop websites as good as possible. But with mobile users now accounting for about 60% of search traffic, it’s necessary to have a responsive, mobile-friendly site.
In fact, Google has since started the mobile-first indexing of websites which means that the mobile version of your website will be indexed first on search engine results.
For nonresponsive websites inadequate to view on mobile devices, they could see a drop in organic traffic as their websites represent a poor user experience for internet users.
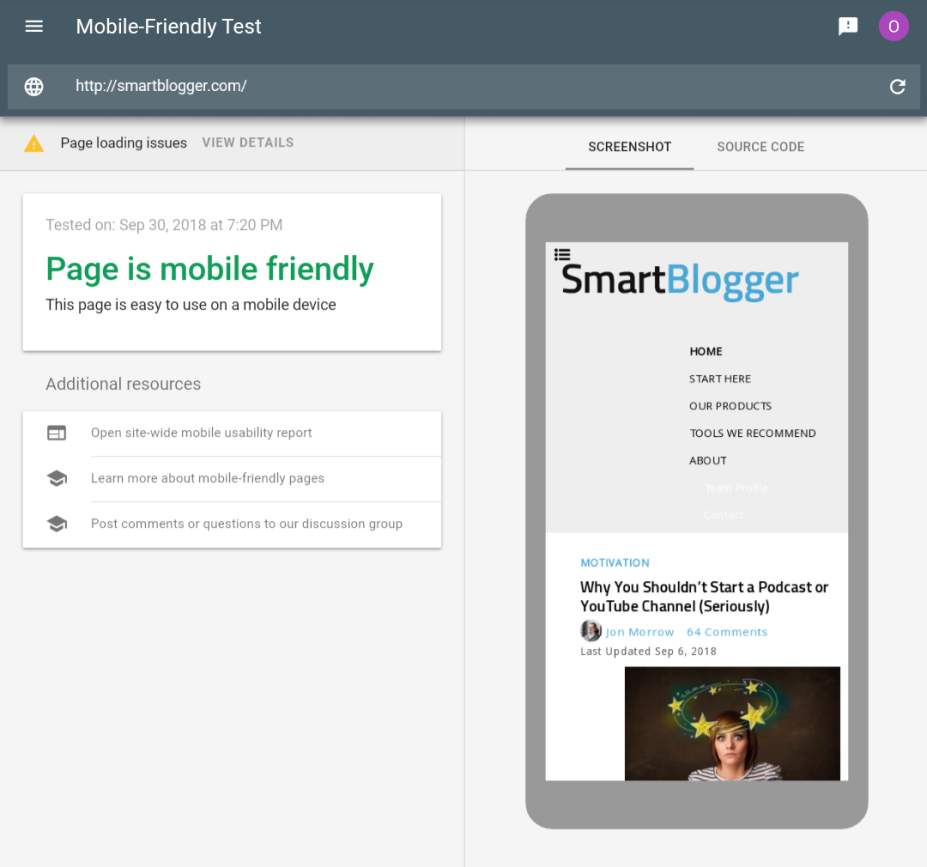
Websites that have mobile-responsive designs have no reason to worry. To check if your website is mobile-friendly, you can use this Google mobile-friendly test:
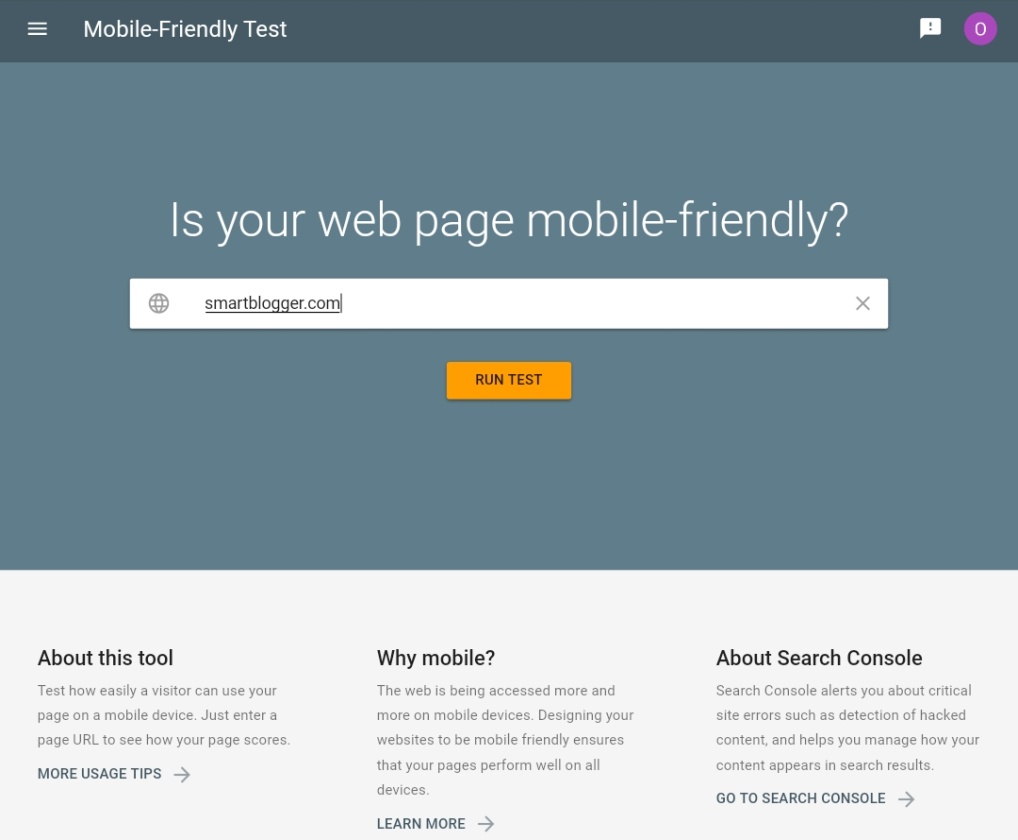
This will show you whether your website is mobile-friendly or not. You’ll also see issues you need to resolve on your website.
Conclusion
To avoid duplicate content and indexing issues on your website, take these steps to inform search engines of your preferred pages. It’s important to make sure your website is indexed to have a chance of a higher ranking with SEO so that people can find your business.
Need some additional help on where to start? This checklist contains some tips to get more organic traffic, leads, and customers for your business.